Unlock Hidden Patterns: The Simple Yet Powerful Solution to Finding Longest Common Substrings
Unlock Hidden Patterns: The Simple Yet Powerful Solution to Finding Longest Common Substrings
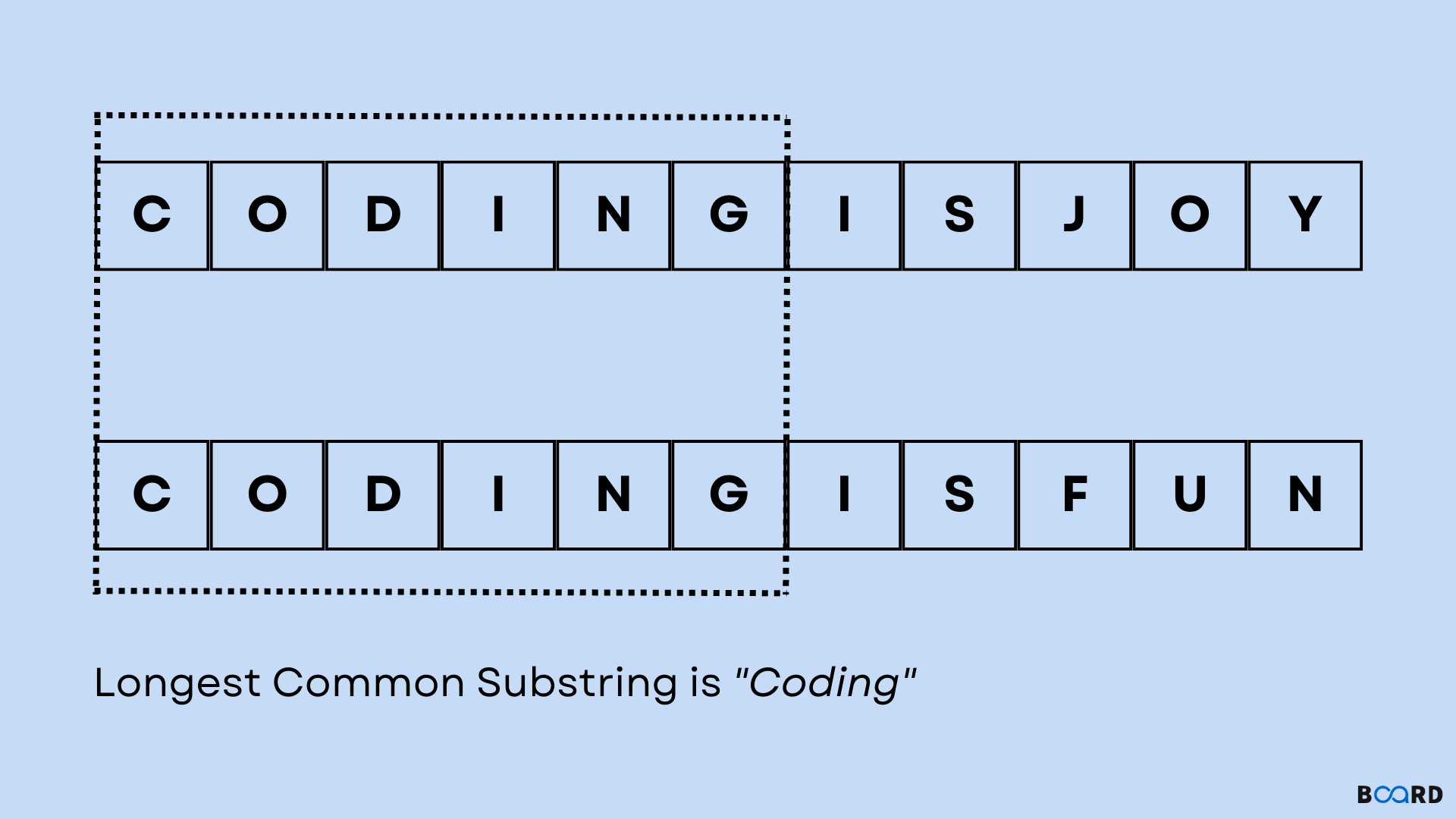
In a world driven by data, the ability to detect similarities across strings—document snippets, DNA sequences, user inputs, or even copyrighted text—hinges on a foundational algorithmic challenge: identifying the longest common substring. Despite its technical roots, the core concept remains remarkably accessible. By leveraging efficient preprocessing and smart comparison, analyzing textual relationships no longer demands complex programming or heavy computational resources.
This breakthrough solution transforms an otherwise daunting problem into a practically executable task, empowering researchers, developers, and analysts alike. The challenge of finding the longest common substring—defined as the maximum-length contiguous sequence present in two input strings—has long attracted attention in computer science. Traditional approaches, such as


Related Post

The Rising Star And Her Impressive Net Worth: A Case Study in Modern Entrepreneurial Success

Replace Your Child’s Social Security Card: A Simple, Safe Process with Critical Safeguards

The Unvarnished Fight: Uncovering the Raw Grit That Defines Modern News and Guts

Exploring The Life And Legacy Of Hisashi Ouchi: The Human Cost Behind The Tokai-2 Nuclear Disaster



